Computer Vision Demo
Practical Implementation of Image Classification with PyTorch using Fashion MNIST Dataset
Created by Murilo Gustineli
Run the Computer Vision Demo in a colab notebook
![]()
References:
- GitHub repo for this notebook
- TensorFlow tutorial: Basic Image Classification
- Training with PyTorch documentation
- Fashion MNIST GitHub repo
- Deep Learning with Python, Second Edition
Welcome to this practical implementation, where we delve into the world of computer vision using PyTorch.
Our goal is to develop a practical understanding of Convolutional Neural Networks (CNNs) by implementing a model that can classify different types of clothing. This demo is designed for learners at all levels, so don’t worry if some concepts seem new. We’ll walk through each step of the process, explaining the key ideas and code details along the way.
1# PyTorch
2import torch
3
4# Helper libraries
5import numpy as np
6import matplotlib.pyplot as plt
7
8# Check if cuda is available
9cuda_availability = torch.cuda.is_available()
10print(f"PyTorch version: {torch.__version__}")
11print(f"Cuda availability: {cuda_availability}")
12
13# Auto-reloading external modules
14# See http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
15%load_ext autoreload
16%autoreload 2
PyTorch version: 2.1.2
Cuda availability: False
1. The Fashion MNIST dataset
In this demo, we use the Fashion MNIST dataset, a modern alternative to the classic MNIST dataset traditionally used for handwriting recognition.
Fashion MNIST comprises 70,000 grayscale images, each 28x28 pixels, distributed across 10 different clothing categories. These images are small, detailed, and varied enough to challenge our model while being simple enough for straightforward processing and quick training times.
| Figure 1. Fashion-MNIST samples (by Zalando, MIT License). |
1.1 Dataset Structure
The dataset is split into two parts:
Training Set: This includes
train_imagesandtrain_labels. These are the arrays that our model will learn from. The model sees these images and their corresponding labels, adjusting its weights and biases to reduce classification error.Test Set: This comprises
test_imagesandtest_labels. These are used to evaluate how well our model performs on data it has never seen before. This is crucial for understanding the model’s generalization capability.
1.2 Understanding the Data
Each image in the dataset is a 28x28 NumPy array. The pixel values range from 0 to 255, with 0 being black, 255 being white, and the various shades of gray in between. The labels are integers from 0 to 9, each representing a specific category of clothing.
Class Names:
The dataset doesn’t include the names of the clothing classes, so we will manually define them for clarity when visualizing our results. Here’s the mapping:
| Label | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
In the following sections, we will load and preprocess this data, design and train a CNN, and finally evaluate its performance on the test set. Let’s get started!
1# Defining class names
2class_names = [
3 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
4 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot',
5]
2. Loading the dataset
Let’s load the Fashion MNIST dataset directly from PyTorch:
1import torch
2from torchvision import datasets, transforms
3from torch.utils.data import DataLoader
4from IPython import get_ipython
5
6# Check if running on Google Colab
7if 'google.colab' in str(get_ipython()):
8 data_dir = '/content/FashionMNIST_data/'
9else:
10 data_dir = './FashionMNIST_data/' # Relative path for local execution
11
12# Define transformation
13transform = transforms.Compose([
14 transforms.ToTensor(),
15 transforms.Normalize((0.5,), (0.5,))
16])
17
18# Seed for reproducibility
19torch.manual_seed(7)
20
21# Create training and validation datasets
22trainset = datasets.FashionMNIST(data_dir, download=True, train=True, transform=transform)
23validset = datasets.FashionMNIST(data_dir, download=True, train=False, transform=transform)
24
25# Create data loaders for our datasets
26trainloader = DataLoader(trainset, batch_size=32, shuffle=True)
27validloader = DataLoader(validset, batch_size=32, shuffle=True)
28
29# Report split sizes
30print('Training set has {} instances'.format(len(trainset)))
31print('Validation set has {} instances'.format(len(validset)))
Training set has 60000 instances
Validation set has 10000 instances
Defining Transformations:
transforms.ToTensor(): Converts the images into PyTorch tensors and scales the pixel values to the range [0, 1].transforms.Normalize((0.5,), (0.5,)): Normalizes the tensor images so that each pixel value is centered around 0 and falls within the range [-1, 1]. This normalization helps in stabilizing the learning process and often leads to faster convergence in deep learning models.
2.1 Using DataLoader
The DataLoader in PyTorch provides batches of data, and you can iterate through these batches to collect all images and labels. This method is memory-efficient and is typically used when dealing with large datasets.
1def extract_images_labels(loader):
2 images = []
3 labels = []
4 for batch in loader:
5 b_images, b_labels = batch
6 images.append(b_images)
7 labels.append(b_labels)
8 return torch.cat(images, dim=0), torch.cat(labels, dim=0)
9
10# Extracting train and test images and labels
11train_images, train_labels = extract_images_labels(trainloader)
12valid_images, valid_labels = extract_images_labels(validloader)
Important Notes:
This method will load the entire dataset into memeory, which is fine for small datasets like the Fashion MNIST, but might not be feasible for significantly larger datasets.
train_imagesandvalid_imageswill be tensors containing the image data, andtrain_labelsandvalid_labelswill be tensors containing the corresponding labels.These tensors are primarily for visualization purposes. For actual model training, especially with larger datasets, it’s recommended to use
trainloaderandvalidloaderdirectly within the training loop to leverage their efficiency and memory-friendly approach.
3. Exploring the data
Before training our model, it’s essential to understand the Fashion MNIST dataset’s format and structure. This understanding helps in effectively tailoring our model and preprocessing steps.
3.1 Understanding the Training Set
Size and Shape of Training Images: The shape of the train_images tensor provides insight into the number of images and their dimensions.
The shape is represented as (N, C, H, W), where:
- N = Number of images
- C = Number of color channels per image (For grayscale images, C = 1)
- H = Height of each image in pixels
- W = Width of each image in pixels
In our dataset, each image is a 28 x 28 pixel grayscale image, so the shape will be (60000, 1, 28, 28), indicating 60,000 images with 1 color channel and 28x28 pixel resolution.
1train_images.shape # Output expected: (60000, 1, 28, 28)
torch.Size([60000, 1, 28, 28])
The “rank” of a tensor refers to the number of dimensions it has. For images represented as tensors, you can find the rank using the .dim() method, which returns the number of dimensions in the tensor.
1train_images.dim() # Output expected: 4
4
- Training Labels: The total number of labels in the training set should match the number of images. Each label corresponds to a category of fashion item.
1len(train_labels) # Output expected: 60000
60000
- Label Range: Each label is an integer from 0 to 9, where each number corresponds to a specific category (like T-shirts, trousers, etc.).
1train_labels # Output example: tensor([9, 8, 3, ..., 7, 7, 6])
tensor([9, 8, 3, ..., 7, 7, 6])
3.2 Understanding the Test Set
- Size and Shape of Test Images: The test set should have a similar structure but with fewer images, typically used for evaluating the model’s performance.
1valid_images.shape # Output expected: (10000, 1, 28, 28)
torch.Size([10000, 1, 28, 28])
- Test Labels: The test set contains labels corresponding to each image, used to verify the model’s predictions.
1len(valid_labels) # Output expected: 10000
10000
4. Data Preprocessing
Before training our neural network, it’s crucial to preprocess the data. This involves scaling the pixel values of the images to a standard range, which helps the network learn more efficiently.
4.1 Understanding Pixel Values:
Each image in the Fashion MNIST dataset is represented in grayscale with pixel values ranging from 0 to 255.
We applied Scaling and Normalization methods so that each pixel value is centered around 0 and falls within the range [-1, 1].
This normalization is often used in deep learning models as it centers the data around 0, which can lead to faster convergence during training. It can also help mitigate issues caused by different lighting and contrast in images.
The value
-1represents black,1represents white, and the values in between represent various shades of gray.
Let’s inspect the first image in the training set displaying these pixel values:
1# Plotting firt image
2plt.figure()
3plt.imshow(train_images[0][0], cmap='gray')
4plt.colorbar()
5plt.grid(False)
6plt.xticks([])
7plt.yticks([])
8plt.show()

1def get_text_color(value:float) -> str:
2 """Returns 'white' for dark pixels and 'black' for light pixels."""
3 return 'white' if value < 0.5 else 'black'
4
5image_numpy = train_images[0][0].squeeze().numpy()
6label = train_labels[0]
7
8# Plotting the image
9plt.figure(figsize=(14,14))
10plt.imshow(image_numpy, cmap='gray')
11plt.title(class_names[label], fontsize=16,)
12plt.grid(False)
13plt.xticks([])
14plt.yticks([])
15
16# Overlaying the pixel values
17for i in range(image_numpy.shape[0]):
18 for j in range(image_numpy.shape[1]):
19 plt.text(j, i, '{:.1f}'.format(image_numpy[i,j]), ha='center', va='center', color=get_text_color(image_numpy[i,j]))
20plt.show()

4.2 Verifying the Data Format:
Before building the model, it’s a good practice to visualize the data to ensure it’s in the correct format. Displaying the first 25 images from the training set can help us confirm that the data is ready for model training.
Additionally, displaying the class name below each image ensures that the labels correspond correctly to the images:
1plt.figure(figsize=(10,10))
2for i in range(25):
3 plt.subplot(5,5,i+1)
4 plt.xticks([])
5 plt.yticks([])
6 plt.grid(False)
7 plt.imshow(train_images[i][0], cmap='gray')
8 plt.xlabel(class_names[train_labels[i]])
9plt.show()

5. Convolutional Neural Networks
In deep learning, especially for tasks like image classification, Convolutional Neural Networks (CNNs) are often the architecture of choice. CNNs are designed to automatically and adaptively learn spatial hierarchies of features from input images.
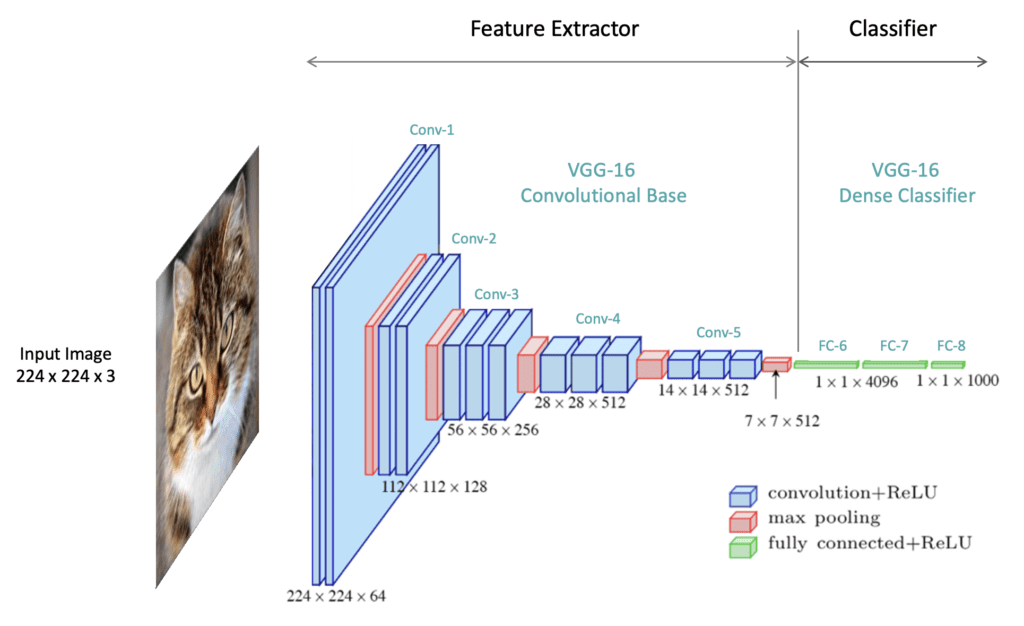 |
| Figure 2. Understanding Convolutional Neural Network (CNN): A Complete Guide (by LearnOpenCV). |
5.1 Hierarchical Compositionality in CNNs
Complex features are built from simpler ones.
In Convolutional Neural Networks (CNNs), the concept of hierarchical compositionality plays a pivotal role. This idea is based on how CNNs learn to recognize and interpret images through layers that understand increasingly complex features:
Low-Level Features: The initial layers of a CNN focus on simple, low-level features such as edges, colors, and basic textures.
Mid-Level Features: As the data progresses through the network, these basic features are combined to form mid-level features, like shapes and specific patterns.
High-Level Features: In the deeper layers, these combinations further evolve into high-level features that represent more complex aspects of the image, such as entire objects or significant parts of them.
 |
| Figure 3. CS 7643: Deep Learning (by Prof. Kira Zsolt, Georgia Institute of Technology). |
This hierarchical approach allows CNNs to build a deep understanding of images from simple to complex, making them highly effective for tasks like image classification.
Extra Resources:
- Paper: Visualizing and Understanding Convolutional Networks
- CNN Explainer: Learn CNNs in your browser!
5.2 CNN Architecture
Let’s construct a CNN suitable for the Fashion MNIST dataset using PyTorch’s torch.nn module. This CNN will consist of convolutional layers for feature extraction followed by fully connected layers for classification.
Here’s how we can structure our CNN:
1import torch.nn as nn
2import torch.nn.functional as F
3
4class CNNClassifier(nn.Module):
5 def __init__(self):
6 super(CNNClassifier, self).__init__()
7 # Convolutional layers using Sequential
8 self.conv_layers = nn.Sequential(
9 # First convolutional layer
10 nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), # 32 filters, 3x3 kernel, stride 1, padding 1
11 nn.ReLU(inplace=True), # ReLU activation
12 nn.MaxPool2d(kernel_size=2, stride=2), # 2x2 Max pooling with stride 2
13
14 # Second convolutional layer
15 nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), # 64 filters, 3x3 kernel, stride 1, padding 1
16 nn.ReLU(inplace=True), # ReLU activation
17 nn.MaxPool2d(kernel_size=2, stride=2), # 2x2 Max pooling with stride 2
18 )
19
20 # Fully connected layers using Sequential
21 self.fc_layers = nn.Sequential(
22 nn.Flatten(), # Flatten the output of conv layers
23 nn.Linear(64 * 7 * 7, 128), # Fully connected layer with 128 neurons
24 nn.ReLU(inplace=True), # ReLU activation
25 nn.Linear(128, 10) # Output layer with 10 neurons for 10 classes
26 )
27
28 def forward(self, x):
29 x = self.conv_layers(x) # Pass through conv layers
30 x = self.fc_layers(x) # Pass through fully connected layers
31 return x
32
33# Create the model instance
34model = CNNClassifier()
Architecture explanation:
Convolutional Layers: The model starts with two sets of convolutional layers, each followed by a ReLU activation and a max pooling layer. The first
Conv2dlayer takes a single-channel (grayscale) image and applies 32 filters. The secondConv2dlayer increases the depth to 64 filters.ReLU Activation: After each convolutional layer, a ReLU activation function is used. It introduces non-linearity, allowing the model to learn more complex patterns.
Max Pooling: Each max pooling layer (
MaxPool2d) reduces the spatial dimensions of the feature map by half, helping in reducing the computation and controlling overfitting.Fully Connected Layers: The output from the convolutional layers is flattened into a 1D vector and then passed through two fully connected layers. The first linear layer reduces the dimension to 128, and the second linear layer produces the final output corresponding to the 10 classes.
This architecture, structured using the nn.Sequential container, offers a clear and compact way to define a CNN in PyTorch. The model is now ready to be trained with the Fashion MNIST dataset.
5.3 Defining the Loss Function and Optimizer
Before training, the model requires a few additional settings, including an optimizer and a loss function:
Optimizer: The optimizer is responsible for updating the model parameters based on the computed gradients. It’s crucial for the convergence of the training process.
Loss Function: The loss function measures the discrepancy between the model’s predictions and the actual labels. During training, we aim to minimize this loss.
Here’s how you set up these components in PyTorch:
1import torch.optim as optim
2
3# Set the loss function
4loss_fn = nn.CrossEntropyLoss()
5
6# Set the optimizer
7optimizer = optim.Adam(model.parameters(), lr=0.001)
Explanation:
Cross-Entropy Loss: We use
nn.CrossEntropyLossfor multi-class classification. This loss function combines nn.LogSoftmax and nn.NLLLoss in one single class. It is suitable for classification tasks with C classes.Adam Optimizer:
optim.Adamis used as the optimizer. It’s a popular choice due to its effectiveness in handling sparse gradients and adapting the learning rate during training.Learning Rate (lr): This is a hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated. Here, it’s set to 0.001.
6. Training the Model
Having defined the model architecture and set up the loss function and optimizer, we now move to one of the most crucial stages in building a machine learning model – training.
Training a model in deep learning involves feeding it data, letting it make predictions, and then adjusting the model parameters (weights) based on the error in its predictions. This process is repeated iteratively and is essential for the model to learn from the data.
- Documentation: Training with PyTorch
6.1 The Training Loop
The core of model training in PyTorch is the training loop. During each iteration (or epoch) of the loop, the model makes predictions (a forward pass), calculates the error (loss), and updates its parameters (a backward pass). Here’s a basic outline of what this process involves:
Forward Pass: The model processes the input data and makes predictions.
Compute Loss: The discrepancy between the model’s predictions and the actual labels is calculated using the loss function.
Backward Pass: Backpropagation is performed to calculate the gradients of the loss with respect to each model parameter.
Update Model Parameters: The optimizer updates the model parameters using the computed gradients.
Training Function
Unlike TensorFlow’s Keras API, which provides high-level functions like model.fit and model.evaluate, PyTorch requires you to explicitly define the training loop and the evaluation process. This approach gives you more control and flexibility but also requires more code.
First, we define a function to encapsulate the training logic for one epoch. This function will handle the forward and backward passes, loss computation, and parameter updates:
1def train_one_epoch(model, trainloader, optimizer, loss_fn, epoch_index, tb_writer):
2 model.train() # Set the model to training mode
3 running_loss = 0.0
4 total_batches = len(trainloader)
5 log_interval = max(1, total_batches // 10) # Log 10 times per epoch or at least once
6
7 for i, data in enumerate(trainloader):
8 # Every data instance is an input + label pair
9 inputs, labels = data
10
11 # Zero the gradients to ensure they aren't accumulated
12 optimizer.zero_grad()
13
14 # Forward pass
15 outputs = model(inputs) # Make predictions for this batch
16 loss = loss_fn(outputs, labels) # Compute the loss
17
18 # Backward pass and optimization
19 loss.backward() # Compute the gradients
20 optimizer.step() # Adjust learning weigths
21
22 # Accumulate loss
23 running_loss += loss.item()
24 if i % log_interval == log_interval - 1: # Adjusted logging condition
25 average_loss = running_loss / log_interval # Average loss per batch in this set
26 print(f" batch {i+1} loss: {average_loss}")
27 tb_x = epoch_index * total_batches + i + 1
28 tb_writer.add_scalar('Loss/train', average_loss, tb_x)
29 running_loss = 0.0
30
31 return average_loss
Validation Function
Next, we add a function to perform validation after each training epoch. This function will evaluate the model on a separate validation dataset:
1import os
2
3# Model validation
4def validate(model, validloader, loss_fn):
5 model.eval() # Set the model to evaluation mode
6 running_vloss = 0.0
7
8 with torch.no_grad(): # Disable gradient computation
9 for inputs, labels in validloader:
10 outputs = model(inputs)
11 vloss = loss_fn(outputs, labels)
12 running_vloss += vloss.item()
13
14 average_vloss = running_vloss / len(validloader)
15 return average_vloss
Early Stopping
Early Stopping is a technique that helps prevent overfitting by terminating the training when the model starts to learn noise or irrelevant patterns in the training data.
1class EarlyStopping:
2 def __init__(self, patience=3, min_delta=0):
3 """
4 Early stops the training if validation loss doesn't improve after a given patience.
5 """
6 self.patience = patience
7 self.min_delta = min_delta
8 self.counter = 0
9 self.best_loss = None
10 self.early_stop = False
11
12 def __call__(self, val_loss):
13 if self.best_loss is None:
14 self.best_loss = val_loss
15 elif val_loss > self.best_loss - self.min_delta:
16 self.counter += 1
17 if self.counter >= self.patience:
18 self.early_stop = True
19 else:
20 self.best_loss = val_loss
21 self.counter = 0
22
23# Initialize the early stopping object
24early_stopping = EarlyStopping(patience=3, min_delta=0.01)
Training and Validation Loop
With these functions in place, we can structure the overall training and validation loop:
1# PyTorch TensorBoard support
2from torch.utils.tensorboard import SummaryWriter
3from datetime import datetime
4
5def train_model(model, trainloader, validloader, optimizer, loss_fn, num_epochs=10, save_model=True):
6 """
7 Runs the training and validation loop for the given model.
8
9 Args:
10 model (nn.Module): The neural network model to be trained.
11 trainloader (DataLoader): DataLoader for the training dataset.
12 validloader (DataLoader): DataLoader for the validation dataset.
13 optimizer (torch.optim.Optimizer): Optimizer for the model.
14 loss_fn: Loss function to use for training.
15 num_epochs (int): Number of epochs for training. Default is 10.
16 save_model (bool): Flag to save the model if validation loss improves. Default is True.
17 """
18 timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
19 writer = SummaryWriter('runs/fashion_trainer_{}'.format(timestamp))
20 train_losses = []
21 val_losses = []
22 EPOCHS = num_epochs
23 best_vloss = 1_000_000.
24
25 for epoch in range(EPOCHS):
26 print(f'EPOCH {epoch + 1}/{EPOCHS}')
27
28 # Training
29 avg_loss = train_one_epoch(model, trainloader, optimizer, loss_fn, epoch, writer)
30 # print(f'Training Loss: {avg_loss:.4f}')
31
32 # Validation
33 avg_vloss = validate(model, validloader, loss_fn)
34 print(f'LOSS train: {avg_loss:.4f} -- valid: {avg_vloss:.4f}')
35 # print(f'Validation Loss: {avg_vloss:.4f}')
36
37 # Log the running loss averaged per batch for both training and validation
38 writer.add_scalars(
39 'Training vs. Validation Loss',
40 {'Training': avg_loss, 'Validation': avg_vloss },
41 epoch+1
42 )
43 writer.flush()
44
45 # Append average losses after each epoch
46 train_losses.append(avg_loss)
47 val_losses.append(avg_vloss)
48
49 # Early Stopping
50 early_stopping(avg_vloss)
51 if early_stopping.early_stop:
52 print("Early stopping triggered")
53 break
54
55 # Check for improvement and save model
56 if save_model and avg_vloss < best_vloss:
57 # Ensure the directory exists
58 saved_models_dir = './saved_models'
59 if not os.path.exists(saved_models_dir):
60 os.makedirs(saved_models_dir)
61 # Save best model
62 best_vloss = avg_vloss
63 model_path = f"./saved_models/model_{epoch}_{timestamp}.pth"
64 torch.save(model.state_dict(), model_path)
65 print(f'Model saved to {model_path}')
66
67 return train_losses, val_losses
1# Train the model
2train_losses, val_losses = train_model(model, trainloader, validloader, optimizer, loss_fn)
EPOCH 1/10
batch 187 loss: 0.7815310352626331
batch 374 loss: 0.48613907572101145
batch 561 loss: 0.3999798647700784
batch 748 loss: 0.36871147040217955
batch 935 loss: 0.35516737118602437
batch 1122 loss: 0.3617793916859091
batch 1309 loss: 0.34854616754673384
batch 1496 loss: 0.3176474018410884
batch 1683 loss: 0.31534920716508824
batch 1870 loss: 0.3031003690339665
LOSS train: 0.3031 -- valid: 0.3254
Model saved to ./saved_models/model_0_20240122_074537.pth
EPOCH 2/10
batch 187 loss: 0.2633895138726834
batch 374 loss: 0.25477837984335616
batch 561 loss: 0.26777994118750414
batch 748 loss: 0.2780310674944026
batch 935 loss: 0.2514276590975211
batch 1122 loss: 0.2670865686620302
batch 1309 loss: 0.2500107698839775
batch 1496 loss: 0.2612737203863534
batch 1683 loss: 0.2562679691827871
batch 1870 loss: 0.2597585876078848
LOSS train: 0.2598 -- valid: 0.2774
Model saved to ./saved_models/model_1_20240122_074537.pth
EPOCH 3/10
batch 187 loss: 0.2182582863033774
batch 374 loss: 0.21429858047933503
batch 561 loss: 0.2213542611004516
batch 748 loss: 0.20720045682899454
batch 935 loss: 0.21772785568460423
batch 1122 loss: 0.2048042686307494
batch 1309 loss: 0.22424145604678017
batch 1496 loss: 0.2157760307710757
batch 1683 loss: 0.22659921588346282
batch 1870 loss: 0.20506563242823683
LOSS train: 0.2051 -- valid: 0.2518
Model saved to ./saved_models/model_2_20240122_074537.pth
EPOCH 4/10
batch 187 loss: 0.17509131173399042
batch 374 loss: 0.18894203200458207
batch 561 loss: 0.1780999759759973
batch 748 loss: 0.18176765804662104
batch 935 loss: 0.1851623724488651
batch 1122 loss: 0.18986983400057345
batch 1309 loss: 0.18469491857975562
batch 1496 loss: 0.18138664159027332
batch 1683 loss: 0.18155848991902754
batch 1870 loss: 0.1737585065358463
LOSS train: 0.1738 -- valid: 0.2676
EPOCH 5/10
batch 187 loss: 0.14732835041906903
batch 374 loss: 0.15089740436947482
batch 561 loss: 0.15200401314678677
batch 748 loss: 0.1536160892742203
batch 935 loss: 0.1623252102965738
batch 1122 loss: 0.15252764867668483
batch 1309 loss: 0.14172770584470287
batch 1496 loss: 0.15746805861213786
batch 1683 loss: 0.1480582723702817
batch 1870 loss: 0.1564132237089748
LOSS train: 0.1564 -- valid: 0.2436
Model saved to ./saved_models/model_4_20240122_074537.pth
EPOCH 6/10
batch 187 loss: 0.12108336666220411
batch 374 loss: 0.12462331514984848
batch 561 loss: 0.12107207644033559
batch 748 loss: 0.12825290896596117
batch 935 loss: 0.12207487767392938
batch 1122 loss: 0.13691178718731206
batch 1309 loss: 0.12671447862039276
batch 1496 loss: 0.13837192698137804
batch 1683 loss: 0.13607694819211003
batch 1870 loss: 0.13199008475580715
LOSS train: 0.1320 -- valid: 0.2568
Early stopping triggered
1# Plotting
2def plot_loss_curves(train_losses, val_losses):
3 fig, ax = plt.subplots(figsize=(6.4, 4.8), dpi=120)
4 fig.suptitle("Training and Validation Loss Over Epochs", fontsize=14, weight='bold')
5 ax.plot(train_losses, linewidth=2, label='Training Loss')
6 ax.plot(val_losses, linewidth=2, label='Validation Loss')
7 ax.set_xticks(np.arange(0, len(train_losses), 1))
8 ax.set_xlabel('Epochs')
9 ax.set_ylabel('Loss')
10 ax.grid(color='blue', linestyle='--', linewidth=1, alpha=0.2)
11 ax.legend(loc="upper right")
12 spines = ['top', 'right', 'bottom', 'left']
13 for s in spines:
14 ax.spines[s].set_visible(False)
15 fig.tight_layout(pad=0.7)
16 plt.show()
17
18plot_loss_curves(train_losses, val_losses)

7. Evaluate Accuracy in PyTorch
Writing a function to calculate the accuracy. We’ll use this function with our validation dataset.
Accuracy Calculation Function
1def evaluate_accuracy(model, testloader):
2 correct = 0
3 total = 0
4 with torch.no_grad(): # Disable gradient computation during inference
5 for data in testloader:
6 images, labels = data
7 outputs = model(images)
8 _, predicted = torch.max(outputs.data, 1)
9 total += labels.size(0)
10 correct += (predicted == labels).sum().item()
11
12 accuracy = 100 * correct / total
13 return accuracy
Using the function to evaluate Validation Accuracy:
1model.eval() # Set the model to evaluation mode
2valid_accuracy = evaluate_accuracy(model, validloader)
3print(f'\nValidation Accuracy: {valid_accuracy:.2f}%')
Validation Accuracy: 91.77%
Explanation of Accuracy in Image Classification
Accuracy is a key metric in image classification that quantifies how often a model correctly predicts the label of an image. It’s expressed as the percentage of test images correctly classified by the model.
Mathematically, accuracy is defined as the ratio of correct predictions to total predictions:
$$ \text{Accuracy}=\frac{\text{Number of Correct Predictions}}{\text{Total Number of Predictions}} $$
Alternatively, using terms from confusion matrix:
$$ \text{Accuracy}=\frac{TP+TN}{TP+TN+FP+FN} $$
Where:
- TP (True Positives): Images correctly identified as belonging to a class.
- TN (True Negatives): Images correctly identified as not belonging to a class.
- FP (False Positives): Images incorrectly identified as belonging to a class.
- FN (False Negatives): Images incorrectly identified as not belonging to a class.
In multi-class settings, such as the Fashion MNIST dataset with 10 classes, accuracy is typically calculated as the ratio of correct predictions to total predictions. The use of TP, TN, FP, FN becomes more relevant in binary classification.
8. Making Predictions
After training your model in PyTorch, you can use it to make predictions on new data. PyTorch models output the logits directly, and you can apply a softmax function to convert these logits into probabilities for easier interpretation.
1# Function to make predictions
2def make_predictions(model, test_images):
3 model.eval() # Set the model to evaluation mode
4 with torch.no_grad(): # Disable gradient tracking
5 logits = model(test_images)
6 probabilities = F.softmax(logits, dim=1)
7 return probabilities
8
9# Make predictions
10predictions = make_predictions(model, valid_images)
8.1 Interpreting Predictions
Each prediction is an array of 10 elements when working with the Fashion MNIST dataset, corresponding to the model’s confidence for each of the 10 classes.
1# Look at the first prediction
2first_prediction = predictions[0]
3print(first_prediction)
4
5# Find the class with the highest confidence for the first prediction
6predicted_class = torch.argmax(first_prediction)
7print(f"Predicted class: {predicted_class.item()}")
8
9# Compare with the actual label
10actual_label = valid_labels[0]
11print(f"Actual label: {actual_label}")
tensor([6.5018e-08, 1.0000e+00, 1.1627e-10, 3.9829e-08, 5.4289e-10, 1.7141e-13,
4.4465e-09, 7.4519e-16, 3.9247e-12, 4.0176e-14])
Predicted class: 1
Actual label: 1
Key Points:
Softmax Transformation: Applying softmax to the logits converts them into probabilities, which sum up to 1. This makes the model’s outputs more interpretable as confidence scores for each class.
Disabling Gradient Tracking: Since we’re only making predictions and not training the model, we disable gradient tracking with
torch.no_grad(), which reduces memory usage and speeds up computations.Model Evaluation Mode: It’s crucial to set the model to evaluation mode (
model.eval()) before making predictions to ensure layers like dropout and batch normalization work in inference mode.Predictions: The predictions are tensors containing the probability of each class. The class with the highest probability is considered the model’s prediction.
8.2 Verify Predictions
With the model trained, you can use it to make predictions about some images.
Let’s look at the 0th image, predictions, and prediction array. Correct prediction labels are blue and incorrect prediction labels are red. The number gives the percentage (out of 100) for the predicted label.
1import matplotlib.pyplot as plt
2
3def plot_image(i, predictions_array, true_label, img, class_names):
4 true_label, img = true_label[i], img[i]
5 plt.grid(False)
6 plt.xticks([])
7 plt.yticks([])
8 plt.imshow(img.squeeze(), cmap=plt.cm.binary) # Assuming img is a PyTorch Tensor
9
10 predicted_label = torch.argmax(predictions_array).item()
11 if predicted_label == true_label:
12 color = 'blue'
13 else:
14 color = 'red'
15
16 plt.xlabel("{} {:2.0f}% ({})".format(
17 class_names[predicted_label],
18 100 * torch.max(predictions_array).item(),
19 class_names[true_label]),
20 color=color
21 )
22
23def plot_value_array(i, predictions_array, true_label, class_names):
24 true_label = true_label[i]
25 plt.grid(False)
26 plt.xticks(range(10))
27 plt.yticks([])
28 predictions_array = predictions_array.numpy()
29 thisplot = plt.bar(range(10), predictions_array, color="#777777")
30 plt.ylim([0, 1])
31 predicted_label = np.argmax(predictions_array)
32 thisplot[predicted_label].set_color('red')
33 thisplot[true_label].set_color('blue')
Now, let’s use these functions to visualize the model’s predictions. We’ll plot both the image and its prediction probability distribution:
1# Example: Visualizing the first image and its prediction
2def plot_single_image_prediction(img_number):
3 plt.figure(figsize=(6,3))
4 plt.subplot(1,2,1)
5 plot_image(img_number, predictions[img_number], valid_labels, valid_images, class_names)
6 plt.subplot(1,2,2)
7 plot_value_array(img_number, predictions[img_number], valid_labels, class_names)
8 plt.tight_layout()
9 plt.show()
10
11plot_single_image_prediction(img_number=0)

1plot_single_image_prediction(img_number=12)

Let’s plot several images with their predictions. Note that the model can be wrong even when very confident.
1num_rows = 5
2num_cols = 3
3num_images = num_rows * num_cols
4plt.figure(figsize=(2 * 2 * num_cols, 2 * num_rows))
5for i in range(num_images):
6 plt.subplot(num_rows, 2 * num_cols, 2 * i + 1)
7 plot_image(i, predictions[i], valid_labels, valid_images, class_names)
8 plt.subplot(num_rows, 2 * num_cols, 2 * i + 2)
9 plot_value_array(i, predictions[i], valid_labels, class_names)
10plt.tight_layout()
11plt.show()

9. Loading a Trained Model
After training your model and saving its state, you can load the model for further inference, evaluation, or continued training. To load a saved model, you’ll need to:
Recreate the Model Architecture: Instantiate a new object of your model class. It’s important that this new model has the same architecture as the one you trained.
Load the Saved State Dictionary: Use
torch.load()to load the saved state dictionary, and then load this state into your newly created model usingmodel.load_state_dict().Documentation: Saving and Loading models using PyTorch
Here’s an example:
1import os
2
3# Step 1: Instantiate the model
4loaded_model = CNNClassifier()
5
6# Step 2: Find the latest model file
7model_dir = './saved_models'
8model_files = [os.path.join(model_dir, f) for f in os.listdir(model_dir) if f.endswith('.pth')]
9latest_model_file = max(model_files, key=os.path.getctime)
10
11# Step 3: Load the saved state dictionary
12loaded_model.load_state_dict(torch.load(latest_model_file))
13
14# Step 4: Switch the model to evaluation mode for inference
15loaded_model.eval()
16
17print(f"Loaded model from {latest_model_file}")
Loaded model from ./saved_models/model_4_20240122_074537.pth
9.1 Test Loaded Model
We can use the loaded model for inference:
1valid_accuracy = evaluate_accuracy(loaded_model, validloader)
2print(f'\nValidation Accuracy: {valid_accuracy:.2f}%')
Validation Accuracy: 91.71%
10. Challenge: Can You Build a Better CNN?
As we conclude this demo, I want to leave you with a challenge that will not only test what you’ve learned but also push the boundaries of your skills in computer vision and deep learning.
Your Mission: Outperform My Model
I’ve walked you through building and training a Convolutional Neural Network (CNN) that achieved a 91% accuracy on the Fashion MNIST dataset. Now, it’s your turn to take the reins. Can you construct and train a CNN that surpasses this benchmark?
Tips for Improvement:
Experiment with Architecture: Try adding more convolutional layers, or adjust the number of neurons in the dense layers. Introduce layers like Dropout or Batch Normalization to see if they help in achieving better generalization.
Tune Hyperparameters: Play around with different learning rates, batch sizes, or optimization algorithms. Sometimes, small changes in these parameters can lead to significant improvements.
Data Augmentation: Use techniques like rotation, scaling, or horizontal flipping to artificially expand your training dataset. This can often help improve the robustness of your model.
Advanced Techniques: If you’re feeling adventurous, explore more advanced architectures like ResNets or Capsule Networks, or delve into newer regularization techniques.
Share Your Results!
Once you’ve built your model, evaluate it on the validation set to see if you’ve managed to outdo the 91% accuracy.
Share your results, along with your unique approach and insights. This is a fantastic opportunity to engage with peers, exchange knowledge, and showcase your skills.